Digital Pooling¶
[Team : Hopper Team] [Tech Lead : amh254] [Service Owner : hr244] [Service Manager : soj23] [Product Manager : bmd42]
Subject Moderation Interface (SMI)¶
This section gives an overview of the Subject Moderation Interface (SMI), describing its current status, where and how it's developed and deployed, and who is responsible for maintaining it.
Service Description¶
The Subject Moderation Interface (SMI) provides a web application for moderating undergraduate applications as part of the Cambridge admissions pooling process. It manages the workflow where applicants who are not offered a place by their initial College can be "pooled" and considered by other Colleges. The service synchronises applicant data from CamSIS, manages applicant document folders across 31 Google Drives (one per College plus Pool Drive), and coordinates pool result data in Google Sheets. Pool results flow back to CamSIS via the SMI API.
Key Features¶
- Web-based subject moderation interface for reviewing undergraduate applications
- Bidirectional applicant data synchronisation with CamSIS (every 30 minutes)
- Automated Google Drive management for 31 College Drives and Pool Drive
- CAPO document upload from CamSIS to Google Drives
- Applicant folder movement between Drives tracking the pooling process
- Subject master spreadsheet (SMS) and subject-specific variant imports
- Django admin console for user and data management
- Google OAuth2 authentication with per-cycle access management
- Cloud Scheduler-driven synchronisation integration jobs (3 distinct live job types and 4 deprecated)
- Backend API for CamSIS to retrieve pool results
- Lookup groups for Google Drive permissions management
User Base & Audience¶
- Cambridge Admissions Office (CAO) — coordinate the pooling process and manage data flows with CamSIS
- College admissions staff — review applicant documents and make pooling decisions via the SMI
- Academics — participate in subject moderation and poolside meetings
Integrations¶
| System | Direction | Description |
|---|---|---|
| CamSIS Integration | Bidirectional | Applicant data feed (in) and pool results (out) via scheduled synchronisation via API |
| Google Drive API | Bidirectional | Manages 31 College Drives and Pool Drive for applicant documents |
| Google Sheets API | Bidirectional | Need calculation data used during the Winter Pool |
| Google Groups / Lookup | Upstream | Drive access permissions managed via Lookup groups synced to Google Groups |
| Cloud SQL (PostgreSQL) | Platform | Applicant data storage |
| GCP Cloud Run | Platform | Application and synchronisation job hosting |
| GCP Cloud Scheduler | Platform | Triggers periodic synchronisation integration jobs |
Data Managed¶
- Applicant records — undergraduate applicant data synchronised from CamSIS including subject choices and college preferences
- Pool results — pooling outcomes flowing back to CamSIS
- CAPO documents — applicant supporting documents stored in Google Drives
- PMOS data — Need calculation data used during the Winter Pool
- IAM — access permissions managed per admissions cycle
Service Status¶
The SMI is currently in live.
Note
The production environment's URLs contain "alpha" because the project started out following the GDS agile phases, but the current phase hasn't been advanced from alpha.
Contact¶
Technical queries and support should be directed to servicedesk@uis.cam.ac.uk and will be picked up by a member of the team working on the service. To ensure that you receive a response, always direct requests to servicedesk@uis.cam.ac.uk rather than reaching out to team members directly.
Google Drives¶
Applicant documents such as CAPOs, transcripts, ECFs are made available to academics and College staff via applicant folders in shared Google Drives. There are 31 Drives in total:
- 29 undergraduate College Drives
- 1 Pool Drive
- 1 Poolside Meetings Drive
Applicant folders and Pools¶
The Poolside Meetings Drive only holds PMOS (Poolside Meeting Outcome Spreadsheet) files. The other 30 Drives hold applicant folders. Applicant folders move between Drives as part of the Pooling process. A pooled applicant's folder will move from their initial College Drive to the Pool Drive and, depending on the outcome of the Pool, back to their original College Drive or to that of a College that 'fishes' them from the Pool.
The pooldrive-synchronisation job is responsible for keeping applicant folders
synchronised with the applicant data in the SMI.
Managing access to Drives¶
Drive permissions are managed using Google Groups which are granted roles on each Drive. The Google Groups are populated from Lookup groups, which is the source of truth for Drive access.
For viewers of the Drives (College staff, academics) we use the uis-digital-admission-pool
Lookup group, which is manually populated at specific points of cycle using a list of
CRSids extracted from the SMI's auth_user table.
Admins (DA devs) are granted access by belonging to per-environment Lookup groups:
- uis-digital-admissions-pool-drive-production-admins
- uis-digital-admissions-pool-drive-integration-admins
- uis-digital-admissions-pool-drive-staging-admins
- uis-digital-admissions-pool-drive-production-admins
These groups all have 'Manager' access on the respective Drives.
All of these Lookup groups are synced to Google Groups by means of a scheduled process maintained by the Identity team. Digital Admissions Google Groups.
Environments¶
Digital Pooling sync jobs & the SMI are currently deployed to the following environments:
| Name | Usage |
Main Application URL | Django Admin URL | Backend API URL |
|---|---|---|---|---|
| Production | Live service | https://alpha.subjectmoderationinterface.apps.cam.ac.uk/ | https://alpha.subjectmoderationinterface.apps.cam.ac.uk/admin | https://alpha.subjectmoderationinterface.apps.cam.ac.uk/api/ |
| Integration | End-to-end testing getting as close to production-like as possible | https://webapp.int.uga.gcp.uis.cam.ac.uk/ | https://webapp.int.uga.gcp.uis.cam.ac.uk/admin | https://webapp.int.uga.gcp.uis.cam.ac.uk/api/ |
| Staging | Manual testing before deployment to production and production-like environments | https://staging.subjectmoderationinterface.apps.cam.ac.uk/ | https://staging.subjectmoderationinterface.apps.cam.ac.uk/admin | https://staging.subjectmoderationinterface.apps.cam.ac.uk/api/ |
| Development | Development playground | https://webapp.devel.uga.gcp.uis.cam.ac.uk/ | https://webapp.devel.uga.gcp.uis.cam.ac.uk/admin | https://webapp.devel.uga.gcp.uis.cam.ac.uk/api/ |
Environment details:
| Environment | Deployment Frequency | User Access | Purpose |
|---|---|---|---|
| Development | An environment to check any development code changes without affecting end-users. | ||
| Integration | An environment to test various interfaces and the interactions between integrated components or systems. | ||
| Test | An environment to evaluate if a component or system satisfies functional requirements. | ||
| Production | An environment where code changes are tested on live user traffic. |
The GCP console pages for managing the infrastructure of each component of the deployment are:
| Name | Main Application Hosting | Database | Synchronisation Job Application Hosting |
|---|---|---|---|
| Production | GCP Cloud Run | GCP Cloud SQL (Postgres) | GCP Cloud Scheduler |
| Integration | GCP Cloud Run | GCP Cloud SQL (Postgres) | GCP Cloud Scheduler |
| Staging | GCP Cloud Run | GCP Cloud SQL (Postgres) | GCP Cloud Scheduler |
| Development | GCP Cloud Run | GCP Cloud SQL (Postgres) | GCP Cloud Scheduler |
All environments share access to a set of secrets stored in the meta-project Secret Manager.
Source code¶
The source code for Digital Pooling is spread over the following repositories:
| Repository | Description |
|---|---|
| Main Application | The source code for the main application Docker image |
| Synchronisation Job Application | The source code for the synchronisation job application Docker image |
| Infrastructure Deployment | The Terraform infrastructure code for deploying the applications to GCP |
Pooling process scripts¶
These are scripts that are used to create resources that enable the Pooling process - Google Drives, Poolside Meeting Outcome Spreadsheets (PMOS).
These were brought into a snippets directory in the Synchronisation Service to keep them under version control and to allow consolidation of common methods. The snippets in this directory are run manually at given points during the application cycle.
| Script | Purpose |
|---|---|
| Create college drives | Creates Google Drives for all colleges and across different environments. |
| Create PMOS sheets | Creates PMOSes for different courses, across different environments and for one of more Pools. |
Technologies used¶
The following gives an overview of the technologies the SMI is built on.
| Category | Language | Framework(s) |
|---|---|---|
| Web Application Backend | Python | Django |
| Web Application Frontend | JavaScript | React |
| Synchronisation Job Application | Python | Flask |
| Database | PostgreSQL | n/a |
| Platform | Unified DevOps Platform |
SMI Operational documentation¶
The following gives an overview of how the SMI is deployed and maintained.
How and where the SMI is deployed¶
Database for undergraduate applicant data is a PostgreSQL database hosted by GCP Cloud SQL. The main web application is a Django backend with React frontend, hosted by GCP Cloud Run. The synchronisation job application (which provides an API with end-points for synchronising the SMI database with other services) uses the Flask library, is hosted by GCP Cloud Run and invoked by GCP Cloud Scheduler.
The SMI infrastucture is deployed using Terraform, with releases of the main application and synchronisation job application deployed by the GitLab CD pipelines associated with the infrastructure deployment repository.
Deployments¶
Digital Pooling follows the divisional deployment boilerplate standard. Container images are pushed to the meta project's Artifact Registry as part of every pipeline on the SMI and Synchronisation Service repositories.
The deployment repo (pools/deploy)
is responsible for actually deploying services. The development & staging environments
default to the 'latest' tag on the master branch, ie. the latest merged code.
The integration & production environments have a specific tag (release) of the code
deployed on them. Terraform locals are used to configure which version is deployed to a
given environment.
Pipelines in the deployment repo run terraform plan for all environments. The job to
run terraform apply is always enabled on pipelines for the master branch. For all
other environments, the apply job being available is contingent on the plan job
succeeding.
The terraform plan job will need re-running for a given environment if the output of
this becomes stale (because the environment state changes) before terraform apply can
be run.
Auto-deployments to staging¶
The SMI and Synchronisation Service repositories are both configured to
automatically run terraform apply against the staging environment each time a
pipeline is triggered on the default branch (usually via a merge request). This
is handled by triggering the pools/deploy pipeline as a downstream job. The
triggered pipeline only contains jobs for the staging environment. To deploy
any other environments a pipeline should be started directly from the
pools/deploy repository.
Deploying a new release¶
To deploy a new release, a new issue is created in the current sprint following this template.
User access management¶
| Environment | User access management |
|---|---|
| Production | Google OAuth2 |
| Integration | Google OAuth2 |
| Staging | Google OAuth2 |
| Development | Google OAuth2 |
However, while being able to use your University Google account to sign in, permissions are initially granted through invitations to the service and managed in the Django Admin console should adjustments be necessary.
In the production environment, all users are removed at the end of an admissions cycle and invitations and permissions re-issued on the start of a new one.
Monitoring¶
- GCP Cloud Monitoring for tracking the health of applications in the environments and sending alert emails when problems are detected.
- Cloud Logs for tracking individual requests/responses to/from the web application and the synchronisation job application:
Debugging¶
The README.md files in each of the source code repositories provide information about debugging
both local and deployed instances of the applications.
Operation¶
Applicant data is initially retrieved from CamSIS via a synchronisation job (managed by GCP Cloud Scheduler which periodically calls the synchronisation job API). Additional annotations are later added by manually importing the subject master spreadsheet (SMS) and subject-specific variants (using the Django admin application page (staging) for the appropriate environment).
Periodic synchronisation jobs ensure that each applicant has an associated folder on Google Drive (for storing additional documents). They also ensure that applicant data is consistent between the SMI and poolside meeting outcome spreadsheets (PMOSs), which are Google Sheets spreadsheets. A manually invoked process on CamSIS uses the SMI web application API to retrieve pooling decisions about applicants, and update the CamSIS database as necessary.
The flow of applicant data to/from the SMI and other services is summarised by the diagram below.
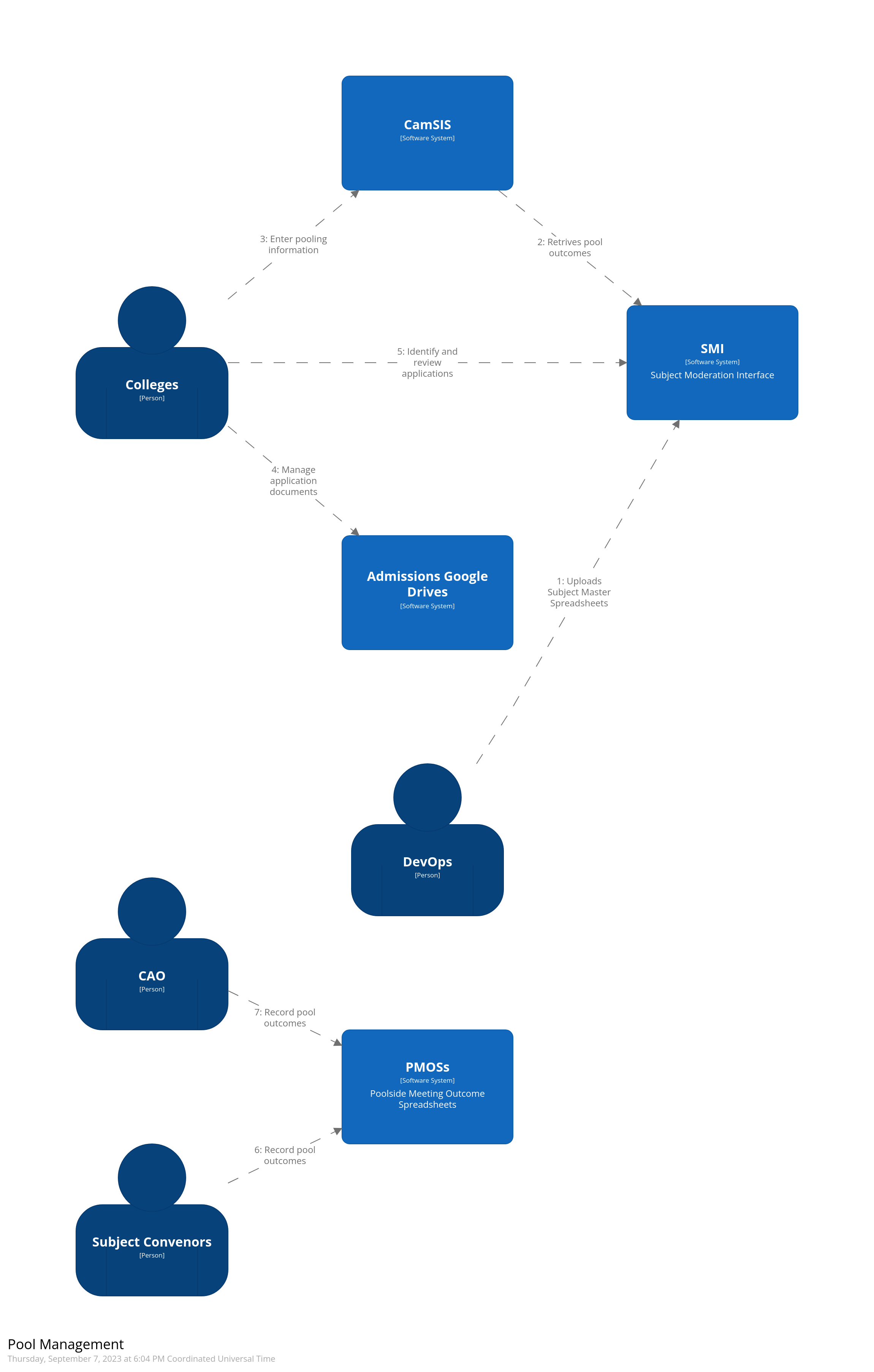
CamSIS environments¶
The following relationship holds between Digital Pooling environments and CamSIS environments:
| Digital Pooling env | CamSIS env |
|---|---|
| production | intb_prod |
| integration | intb_reg |
| test (staging) | intb_test |
| development | intb_dat |
The mapping between Digital Pooling and CamSIS environments is defined by the camsis_environment
lookup in pools/deploy/locals.tf.
Synchronisation jobs¶
A number of synchronisation jobs enable the flow of data during Pools. The table below
shows the frequency with which they run when enabled on production. Jobs may be enabled
or disabled throughout the application cycle and at important points during a Winter or
Summer Pool.
Switching any job on/off during a Pool must be done in co-ordination with CAO to ensure that the right data is present in the CamSIS feed and that it is happening at the right time.
| Name | Frequency | Description |
|---|---|---|
| camsis-synchronisation | Every 30 mins, on the hour | Insert, update, or delete SMI applicant records based on the /SMIApplicantData.v1 CamSIS feed. |
| capo-synchronisation | Every 30 mins, on the hour | Upload CAPOs from CamSIS to the Pool Google Drives. |
| pmos-export-summer-synchronisation | Every 30 mins, at five past | Summer Pool: update the SMI with data from PMOSes. Creates Pool Outcomes in SMI. |
| pmos-export-winter-synchronisation | Every 30 mins, at five past | Winter Pool: as above. |
| pmos-import-summer-synchronisation | Every 30 mins, on the hour | Summer Pool: update PMOSes with data from SMI, creating and updating applicant rows. |
| pmos-import-winter-synchronisation | Every 30 mins, on the hour | Winter Pool: as above. |
| pooldrive-synchronisation | Every 30 mins, on the hour | Creates applicant folders in Google Drive and moves them around. May be enabled at times the camsis-sync is running, not exclusive to Pools. |
Service Management¶
The Team responsible for this service is Hopper Team.
The Tech Lead for this service is amh254.
The Service Owner for this service is hr244.
The Service Manager for this service is soj23.
The Product Manager for this service is bmd42.
The following engineers have operational experience with this service and are able to respond to support requests or incidents: